Nov 16, 2023
At ngrok, we use Dagster to orchestrate (almost) our entire data stack. In this post, we’ll give you a quick overview of how Dagster helps us keep a lot of data streams under control and how we get insights from them.
An overview of ngrok’s Data Platform
ngrok’s Data Platform is the source for insights into how our users use ngrok to power their apps. We use that data to see how to make ngrok a better user experience. The Data Platform is also the tool we rely on when we investigate suspected abuse or fraud, answer difficult support questions, or report financials. Needless to say, the Data Platform is quite an essential piece of the puzzle for the day-to-day operations surrounding cost, abuse, and product-driven decisions.
Our stack depends on a mix of open source software and AWS tooling. We rely on Apache Iceberg for data storage, AWS Athena for a query engine, dbt for data modeling, a mix of Apache Spark + AWS Glue for complex workloads, as well as a mix of Apache Kafka + AWS Kinesis for our streaming needs. Our language stack is a mix of Python, Scala, and SQL. We also host both Airbyte and Dagster’s respective Open Source versions on our own Kubernetes infrastructure, using our ngrok Ingress Controller for Kubernetes.
To give you some numbers: We manage an influx of about 20TB of net new data each month in over 400 Dagster assets and about 170 distinct dbt models.
What is Dagster?
Dagster is an open source data orchestrator and workflow management framework.
What makes Dagster special is its focus on data as assets and its emphasis on proper software engineering standards for data pipelines.
Instead of modeling abstract tasks into graphs, like other tools, Dagster takes the approach of viewing the result of your data - that is, tables, files, and machine learning models - as valuable data assets.
These assets often depend on one another and have freshness guarantees.
And, they must be executed somewhere, preferably without managing a KubernetesPodOperator in code, like Airflow.
That whole system is wrapped into a convenient Python SDK with mostly decorator-based ergonomics and a whole set of helpful features, such as I/O managers for different cloud platforms, a large set of existing integrations, and generally very pleasant developer ergonomics.
For instance, this is how we can extract data from a custom third-party system:
1# Grab data with some custom Python code2@asset(3 group_name="partner_data",4 compute_kind="python",5 description="Read the partners database",6)7def partners_db() -> PartnerData:8 partner_client = Client(auth=auth_token)9 return PartnerDatabaseParser(parner_client).fetch(_db_id)10 11# ... write to S3, add metadata, ...12 13# Execute a dbt asset that models this data14@dbt_assets(15 manifest=DbtMeta.dbt_manifest_path,16 select="ngrok.staging.partners.stg_partners__partner_db",17)18def stg_partner__partner_db(context: AssetExecutionContext, dbt: DbtCliResource):19 yield from dbt.cli(20 ["build", "--select", "ngrok.staging.partners.stg_partners__partner_db"],21 context=context,22 ).stream()Our Dagster codebase is fully integrated into the same engineering infrastructure as the core ngrok product - with unit tests, linters, formatters, static code analysis, container builds, vulnerability scans, dependency scans, integration into operations and on-call tooling, and everything else you would expect from a modern development stack.
Where only a few years ago, software development best practices didn’t really exist for data tools, tools like Dagster and dbt show that it’s not only possible to change that but also that it is hugely beneficial to do so. Code and data quality tend to correlate heavily.
Fun fact*: Most of our developers use remote Linux VMs. We use ngrokhttp 3000 —oauth-allow-email=…
+dagster dev` during local development to make a local version of Dagster available for us to test!
How Dagster helps us orchestrate everything
Before we deployed Dagster, we relied on a mix of scheduling and processing tools with very little monitoring in between and no concept of data lineage. As you can imagine, hunting down the root cause for data issues - such as stale data - was often like looking for a needle in a haystack.
Nowadays, we use Dagster to orchestrate (almost) all our ETL (Extract-Transform-Load) and ELT (Extract-Load-Transform) processes and run the entire end-to-end data flow through it. We also connect it to Sentry to alert us about any possible failures.
For instance, to get data from Salesforce, we grab it via Airbyte, write it to S3 as nested json, and use Spark to process the resulting data into Apache Iceberg, which gets then used in various data models, for which we use dbt.
That makes three distinct components that all rely on one another and can’t stand alone - and that’s before we even talk about data modeling.
Using Dagster’s various integrations, we can use dagster-airbyte to schedule and monitor the ingestion job, use some custom code with dagster-aws to talk to AWS Glue, and use dbt to use the resulting data in our models.
For instance, here is a screenshot of a simple pipeline that processes the aforementioned Salesforce data from Airbyte into various dbt models:
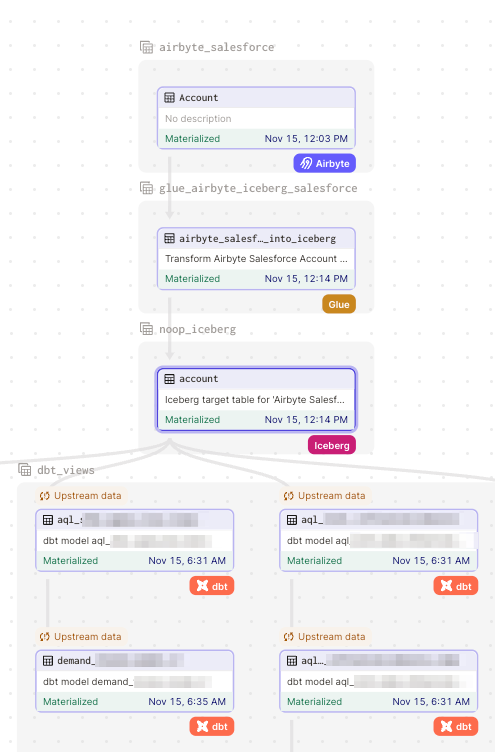
These integrations are mostly automatic. We use a very thin Python abstraction on top of Dagster that models the relationships for us, so we don’t need to modify Python code to add a new Airbyte job.
Embracing dbt
Because Dagster sees data as what it is - a set of assets - one of our use cases was to make Dagster aware of all the various SQL tables and views our users created, with or without their upstream sources.
We had (and have!) a lot of those tables and views, and they often model important information within ngrok. Before dbt and Dagster, our users would write SQL and directly execute it in the Athena Web UI.
But keeping track of the relationship between these assets was challenging. Some models were left mostly undocumented, whereas others had some form of manual lineage documentation.
This is where dbt comes in. dbt allows us to store our SQL models in a git repository and make SQL transformations part of our regular development workflow.
One of the most useful features here is dbt’s approach to modularity.
SQL queries are templated and can refer to other dbt models (or underlying source tables) via a ref function.
Using dbt’s ref() function, we could teach dbt about the relationship between the existing SQL tables and views.
To automate onboarding onto dbt from manually managed Athena views, we wrote a small program that parses our existing SQL into an abstract syntax tree (AST) to extract all references to other tables and replaces those with dbt source() and ref() functions.
Once we had all our models translated into dbt models, we could use dbt docs to visualize lineage.
For instance, take this rather involved view that tracks some metrics for the fiscal year:
But we still needed a way to connect this data to their sources - which aren’t always other dbt models, so this doesn’t tell the whole story.
Dagster + dbt = ❤️
Meet Dagster’s dbt integration! With dagster-dbt enabled, we could use Dagster to automatically parse all our dbt assets into the same handy dependency graph.
Take a look at the same model again:
What makes the Dagster integration an awesome superset of pure dbt is how it can figure out that a source() function in dbt that happens to share an AssetKey with an existing Dagster asset points to a different source, even outside of dbt (like Salesforce)!
The following image from dbt’s docs explains that process:
For instance, by defining a SQL statement like the one below that joins on the salesforce.user table, Dagster would create an asset as salesforce/user, which does show up in the lineage graph, but has not much more metadata available - it’s just a reference to a dbt source, which isn’t managed by dbt itself.
1left join {{ source("salesforce", "user") }} u on (o.ownerid = u.id)For instance, you’d get a mostly empty asset definition like this unless you manually define more details in dbt’s sources.yml:
But if we overwrite the same key with a different asset - say, a reference to a table that we created via a Spark job (which we also orchestrate via Dagster, by the way) - dagster-dbt automatically picks this up and replaces the source() reference with the asset we created earlier with all metadata it has available - like magic.
Note how, this time, we get custom metadata, descriptions, and upstream lineage:
While the asset itself is a NoOp (since Spark is doing the actual work of creating and managing the underlying Iceberg table), we can still track a model’s entire lineage. And since Dagster orchestrates the Spark job, it also won’t run any of the dependent dbt models if the Spark job were to fail so that users won’t get misleading data presented to them!
By following this approach (and being very deliberate and descriptive with AssetKey naming conventions), we turned our existing data model into a fully modeled Dagster dependency graph with a very manageable amount of Python code.
Dagster + ngrok ingress controller = ❤️
Since we already run a large, globally distributed infrastructure here at ngrok, we decided to host Dagster on our own Kubernetes infrastructure.
Dagster has a very clever deployment model that separates the “core” Dagster service from independent user code repositories. That way, you can have separate teams that can all deploy their code independently without ever touching the Dagster web deployment.
Here are the components that are involved in a typical Kubernetes deployment:
source: https://docs.dagster.io/deployment/guides/kubernetes/deploying-with-helm
All we had to do was take the Dagster Helm chart and deploy it on our infrastructure.
Then, we needed to provide ingress to the Dagster Web UI.
Naturally, we wanted to dogfood our product, and we could easily do that by deploying the ngrok Ingress Controller for Kubernetes. ngrok is an ingress-as-a-service platform that establishes secure connectivity to your services.
It handles everything involved with ingress, including DNS entries to TLS certificates, from load balancing to circuit breaking. ngrok collapses the complexity of ingress into a single configurable solution.
We deployed the ngrok Ingress Controller as a Helm chart. Then, we configured the Kubernetes Ingress object to include the ngrok OAuth module, requiring user authorization to access our Dagster instance.
This is done by adding an annotation for ngrok-managed-oauth as seen below.
1apiVersion: networking.k8s.io/v12kind: Ingress3metadata:4 name: dagster-ingress5 labels:6 helm.sh/chart: dagster-1.5.17 app.kubernetes.io/name: dagster8 app.kubernetes.io/instance: dagster9 app.kubernetes.io/version: "1.5.1"10 app.kubernetes.io/managed-by: Helm11 annotations:12 k8s.ngrok.com/modules: "ngrok-managed-oauth"13spec:14 ingressClassName: ngrok15 tls:16 rules:17 - host: ${DAGSTER_URL}18 http:19 paths:20 - path: /21 pathType: ImplementationSpecific22 backend:23 service:24 name: dagster-dagster-webserver25 port:26 number: 80That way, both our production as well as our development instances are now protected from unauthorized access, all with the exact OAuth scopes we defined.
Learn more
Now that you’ve seen how we use Dagster internally at ngrok alongside the ngrok Ingress Controller for Kubernetes, I recommend the following resources to learn more about Dagsters, dbt, and our Ingress Controller.
-
Try the ngrok Ingress Controller for Kubernetes: Check out our guide on protecting your production deployments with our ingress controller!
-
Dagster: Read up on all the cool things Dagster can do
-
dbt: And make sure to check out dbt, too!
Questions or comments? Hit us up on X (aka Twitter) @ngrokhq or LinkedIn.