May 7, 2025
05-07-2025: We updated this with new information about how AI bots might find your endpoints and more nuanced blocks using IP categories from IP Intelligence.
Here’s a simple scenario: You have an ngrok endpoint available on the public internet. No IP restrictions, no authorization blockade from basic to OAuth, no nothing.
You might think your ngrok endpoint is functionally “dark” from the public internet. If no one knows the domain name, and you’re using the ngrok endpoint only for internal use, surely no one or automated bot would be accessing (and potentially using) the data you make available there. Right?
Some of our users have found the opposite is true. ngrok endpoints, which they thought were hidden, are actively crawled and indexed by search engine bots and AI bots looking for more data to refine their models against. If you load up your Traffic Inspector, you might find the same hints of bot traffic.
These intrepid developers have been looking for answers to preventing this unwanted access, and now you might be, too—luckily, I can help you with a few options available ngrok’s Traffic Policy engine.
How and why are bots accessing ngrok endpoints?
First, let’s discuss these bots to give you some context about your targets and why you might want to block them.
This shouldn’t come as much of a surprise: Search engine providers, AI companies, content scrapers, and many other entities use bots to automatically crawl as much of the public internet as possible to hoover up relevant data. They can always follow public hyperlinks to find new pages to crawl, but what about these “private” ngrok endpoints?
The common way these companies find new endpoints, whether they use an ngrok domain (example.ngrok.app) or a custom domain, is through Certificate Transparency (CT) logs.
Every time a domain receives a TLS certificate from a service like Let’s Encrypt, which is what ngrok uses, it’s added to a (very) long, append-only log that helps guarantee these Certificate Authorities remain trustworthy, and your connections secure.
CT logs are great for the health of the public internet, but they’re also an excellent source of fresh domains for AI bots and scrapers to look at next.
As far as what bot traffic hits ngrok endpoints in aggregate, we can query our data lake to see that ChatGPT is the biggest culprit of these types of automated crawls.
But out of the box, ngrok purposely doesn’t:
- Deploy a
robots.txtfile on your behalf, which tells crawlers and bots which URLs they’re allowed to access - Otherwise block any traffic on your endpoint that you haven’t explicitly configured.
If you’re seeing bot traffic on your ngrok endpoint and you’d rather not, Traffic Policy gives you the power to battle against them.
Option 1: Block bots with a robots.txt file
First, if you don’t feel like adding a robots.txt file on the app or service running on your ngrok endpoint, you can ask ngrok to do it on your behalf.
The policy below filters any traffic arriving to ${YOUR-NGROK-ENDPOINT}/robots.txt and serves a plaintext custom response.
If you haven’t configured a policy using the Traffic Policy engine before, check out our docs for examples based on how you deployed ngrok. These policies are compatible with the agent CLI, various SDKs, and the ngrok Operator.
1on_http_request:2 - expressions:3 - "req.url.contains('/robots.txt')"4 actions:5 - type: custom-response6 config:7 body: "User-agent: *\r\nDisallow: /"8 headers:9 content-type: "text/plain"With this policy, any respectable bot traffic looking to crawl your endpoint will first see that you’ve disallowed it on all paths with the following two lines:
1User-agent: *2Disallow: /You could also make your robots.txt more specific.
For example, if you want to only block the OpenAI crawlers ChatGPT-User and GPTBot:
1on_http_request:2 - expressions:3 - "req.url.contains('/robots.txt')"4 actions:5 - type: custom-response6 config:7 body: "User-agent: ChatGPT-User\r\nDisallow: /\r\nUser-agent: GPTBot\r\nDisallow: /"8 headers:9 content-type: "text/plain"Now, the reality is that your robots.txt is not completely bot-proof—even Google’s crawling and indexing documentation states clearly that it’s not a mechanism for keeping a web page from being accessed or even indexed in Google searches.
The same probably applies to AI crawlers like OpenAI—for that, you need to take your bot-blocking to another level.
Option 2: Block the user agents of specific bots
Next, you can instruct ngrok to filter traffic based on the user agent of incoming requests, disallowing certain bot traffic while keeping “human” traffic around.
1on_http_request:2 - expressions:3 - "(req.user_agent.name == 'GPTBot') || (req.user_agent.name == 'ChatGPT-User')"4 actions:5 - type: denyThis rule matches against all requests with a user agent containing chatgpt-user or gptbot and serves a 404 response, preventing them from accessing your ngrok endpoint and crawling or utilizing your data for any reason.
The bonus here is that you can still allow your legitimate human users from accessing the endpoint with user agents you approve of, like curl requests or via a browser.
You can extend the list of user agents to match against like so: (chatgpt-user|gptbot|anthropic|claude|any|other|user-agent|goes|here).
Or, you can take all the guesswork out of the equation with some syntactic sugar and req.user_agent.is_bot.
1on_http_request:2 - expressions:3 - "req.user_agent.is_bot"4 actions:5 - type: denyOption 3: Block all traffic from the IPs of certain organizations or ASNs
Unfortunately, there’s no guarantee bots will 1) read and respect your robots.txt , or 2) not spoof their user agent to skirt around your block.
That’s where the categories of IP Intelligence—our system for enriching the structured logs you can find in Traffic Inspector—come in.
You can quickly block entire IP ranges, and keep them up-to-date, without having to maintain the lists yourself.
Let’s say you want to explicitly block IP addresses owned by OpenAI from accessing your endpoints:
1on_http_request:2 - expressions:3 - "'com.openai' in conn.client_ip.categories"4 actions:5 - type: denyNot worried about OpenAI?
We have dozens of other organizations you can restrict in a few lines of YAML, including the Bad ASN List on GitHub, which we make available with the public.brianhama.bad-asn-list variable.
Maybe you want to block bad ASNs alongside OpenAI:
1on_http_request:2 - expressions:3 - "('com.openai' in conn.client_ip.categories") || ('public.brianhama.bad-asn-list' in conn.client_ip.categories")"4 actions:5 - type: denyOr, you might want to get more nuanced by looking at the logs of Traffic Inspector. If a request hits your endpoint from an IP address that’s on a blocklist we’ve added to IP Intelligence, we flag it with a small inline warning symbol. If you click on the request, then the IP Intelligence tab, you can find more information on the attached categories.
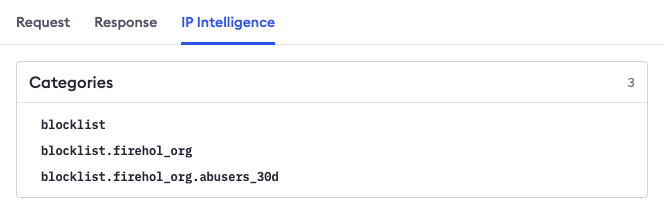
You could then take direct action on this IP and any others flagged by public blocklists as known bots or abusers.
1on_http_request:2 - expressions:3 - "'blocklist.firehol_org.abusers_30d' in conn.client_ip.categories"4 actions:5 - type: denyWhich bot-blocking method should you pick?
If you want the endpoint to be fully accessible to the public internet, but just want to turn away bots with minimal impact, the first option will prevent future bots from constantly pinging your service and showing up in your Traffic Inspector or other logs.
If you want the endpoint to be fully accessible to the public internet, but want to ensure specific bots can’t ignore your robots.txt and crawl your content anyway, the second option will do the trick.
If you want to very explicitly turn away specific IP addresses, but not have to worry about maintaining a denylist, you should implement category-based restrictions with IP Intelligence.
But, you also don’t have to choose just one method! Traffic Policy actions run in sequential order, which means you can also chain them together to:
- Inform bots to not crawl or index any path on the domain name associated with your ngrok endpoint.
- Actively block bots that attempt to crawl your endpoint despite your ngrok-supplied
robots.txt“warning.” - Deny all traffic from an OpenAI IP address.
1on_http_request:2 - expressions:3 - "req.url.contains('/robots.txt')"4 actions:5 - type: custom-response6 config:7 body: "User-agent: ChatGPT-User\r\nDisallow: /\r\nUser-agent: GPTBot\r\nDisallow: /"8 headers:9 content-type: "text/plain"10 - expressions:11 - "(req.user_agent.name == 'GPTBot') || (req.user_agent.name == 'ChatGPT-User')"12 actions:13 - type: deny14 - expressions:15 - "'com.openai' in conn.client_ip.categories"16 actions:17 - type: denyWhat’s next?
Blocking bots is just one example of the powerful and flexible ways you can configure Traffic Policy actions, whether you’re using ngrok as a development tool for webhook testing or in production as an API gateway or for Kubernetes ingress. Traffic Policy and endpoints are all available on the free plan, so give it a shot, won’t you?
Then check out some of our other resources to learn more:
- Traffic Policy documentation
- A gallery of even more examples to block unwanted requests
- Using the
set-varsaction to block multiple lists or JA4 fingerprints at once
Questions on bot-blocking and beyond with ngrok? Our customer success team will happily chat you through your options.
Finally, a big kudos to Justin, our Senior Technical Support Engineer, for bravely fording into the bot-battle to create the first solution based around
robots.txt. 🦾