Aug 13, 2025
Here at ngrok, we have a complex monorepo made up of go, typescript, python, proto, scala, and more.
Our developers utilize standardized developer instances and tooling to enable working with this diverse set of technologies, plus a local environment that attempts to imitate production as closely as possible.
We can’t expect every developer to understand the complexities of software development here at ngrok from day one, and with our dev tool nd, they don’t have to!
But nd isn’t perfect, so we constantly improve our tooling under a few guiding principles:
- Expose what devtools actually invoke
- Make problems more “Google-able”
- Simplify problem-solving with helper commands
- Add introspection for everything
Here’s how we implement them.
First: What is nd?
nd is the primary CLI tool that developers here at ngrok use every day to build, test, and deploy software.
It acts as a contract for the software development lifecycle (SDLC).
Whatever the task might be, ideally nd has a well-trodden path for them to take.
With nd, developers shouldn’t need to know how to build or deploy a service; they just need to know what service they want to interact with, and nd helps whether go, webpack, bazel, or docker builds that service.
Likewise, deploying a service automatically checks if it was built, and if not, nd will build it for them (or warn them if it’s production-bound and they want a CI build instead).
This often allows the underlying logic of “how” to swap without devs needing to change their usual commands.
For example our frontend team was able to help us move from node to bun for some workflows without changing the public commands.
nd is built to complement our developer environment.
We manage our tooling via direnv and nix, which means we can add, remove, or update packages in a commit, growing nd to use them as our SDLC process evolves.
nd isn’t just a tool for our developers to consume; it’s built to be extendable by anyone at ngrok.
While the Infra team maintains it, all of ngrok’s engineers contribute to it.
And since it lives inside our monorepo, every commit is tied to the version of nd that knows how to work with it: They always get the right tool for the job.
How we help developers build services across environments
Our developers run local k3s instances with the full stack of services deployed to them that tries to mimic what prod might look like (swapping out cloud specific parts for local versions where appropriate). These clusters come fully set up on their developer instances when provisioning one so that they can quickly begin working with the systems.
If they want to update it to the current state of their repo, they simply nd env create.
This presents them with a live environment with everything from their branch running in a k3s cluster.
They can now make code or configuration changes then build, test, and deploy their service.
1nd svc build <svc> # build a service2nd bazel test # run unit tests3nd svc deploy <svc> # local deploy4nd svc logs <svc> # inspect logsIf they want to rerun the same set of e2e tests that run continuously in our remote environments:
nd e2e # run end-to-end testsOnce satisfied, a developer might wish to test their code change out in dev.
Doing so is much like the process they used locally.
Our developers simply set their NGROK_ENV to the right environment and invoke nd again.
1export NGROK_ENV=dev2nd svc deploy <svc>That’s the exact same command they used locally, just in a different environment.
Now they can observe the logs via nd or view observability metrics in Datadog.
Moving on, once they merge their PR, our CI platform Buildkite handles deployments to our remote environments.
Developers can trigger their service deployments either via nd svc deploy --with-buildkite (setting their NGROK_ENV to dev, stage, or prod) or they can trigger them via the Buildkite web UI, which also calls nd directly.
Deploying via the CI pipeline has some advantages versus deploying locally.
Other developers can view the progress of a rollout, developers are notified of the rollout progress via Slack, and the pipeline avoids issues we’ve had in the past like interrupted sessions from a developer losing internet access mid-deploy.
Using nd everywhere gives us the best of all possible worlds: We can let developers choose exactly which path they want to take depending on their preferences or ergonomics, but the end result to our CI pipeline is the same consistent process no matter how you got there.
Improvement: More deeply expose what happens beneath the golden path
The golden paths that we lay out for our developers are great, until they aren’t. Sometimes things do go wrong, or a developer encounters a situation nd wasn’t built to handle. While we want nd to be easy to use and allow our developers not to have to worry about the underlying tools, we don’t want it to be a complete black box. We want to make sure developers can peek under the hood without falling into it.
Take the nd svc logs <svc> command for example.
This actually calls an underlying command like:
kubectl --kubeconfig ... logs --namespace controlplane --all-containers -l=app.kubernetes.io/instance=apiWhen the developer runs the nd command, we print the running command for them in hint text (lightly greyed output that they can ignore if they wish).
If they need to tweak this command, the developer can use our kubectl wrapper, nd k, which handles some of the minutia for them, such as setting up auth.
nd k -r us -- logs --all-containers -l=app.kubernetes.io/instance=apiIf they’re a power user of the kubectl command, no problem!
They can run the kubectl command directly, provided they can handle whatever setup is needed to make that work.
nd doesn’t have to be a perfect abstraction of the thing underneath.
It can be opinionated, but developers can then make adjustments or harness the actual raw tool if they want.
If they find themselves using the same customizations again and again, chances are another engineer is doing the same, and we encourage them to contribute their tweaks back into nd as a different option or to change the default for everyone.
Improvement: Add more ‘Google the problem’-ability
One problem with a custom tool that does everything for you is when it doesn’t work, it can be much harder to know why.
Previously, nd generated and maintained build commands like go build, cargo, webpack, etc. These build commands were constructed through layers and layers of abstractions and configuration depending on the service.
As our current Infra team looked for ways to improve nd as a platform, we agreed that we didn’t want our developers to have to decipher a homegrown build system’s logic to figure out how that build command was constructed.
nd should defer to expert tooling on how to do something.
Just as we use kubectl get logs in the previous section (kubectl being an expert tool in that domain), we wanted to level up and ease our maintenance burden with Bazel, the build tooling born at Google.
The other important win we had here was in the discoverability—nd simply delegates:
bazel build //... --build_tag_filters=<svc>Now nd doesn’t need to know all the options, it just needs to know bazel build/test/run.
We surface errors from bazel, which means they’re public, consistent, and searchable.
The developer (or the infra team) can Google their way out of a problem much faster.
Bazel also enabled us to build faster. While repeated builds of the same software are generally fast on any given developer’s machine, new builds were often quite slow because we always had to build from scratch. Bazel gave us incremental, remote caching, which enables us to share the results of build work between CI and developers, reduce the work any given build had to do, and ultimately make all builds faster.
Improvement: Add better helper commands when things go wrong
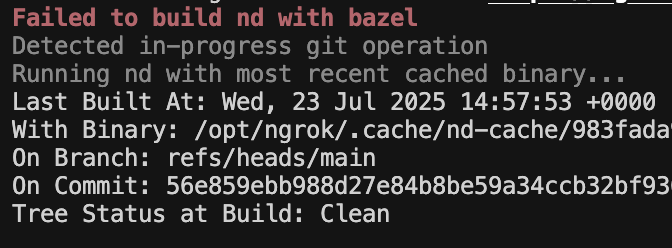
What happens when bazel can’t build nd?
We’ve got the developer’s back.
Every developer has access to the last known good build of nd, cached locally:
$NGROK_DATA/nd-cache/latestWhen nd fails to build, we can either automatically run the last known good build, or suggest the developer re-run the command and helpfully print the exact invocation of nd they need to run the same command using this cached build.
$NGROK_DATA/nd-cache/latest svc logs apiIt’s not perfect, and it might not match the expected current repo state, but it’s good enough to let developers recover, run diagnostics, or tidy things up.
Speaking of which: nd devenv tidy helps developers clean up their devboxes (all those builds pile up plenty of cached outputs).
We even suggest developers run this on opening their shell if nd notices certain metrics are high.
We also have nd diagnose --gist, which collects key system info memory usage, platform info, and even the state of their local cluster, and uploads it as a private gist to their GitHub account, enabling Infra to debug issues.
We don’t expose those gists publicly for security purposes, but they’re a critical feedback loop for improving nd and solving common issues developers might face.
Before this, when developers would ask why something wasn’t working, we’d have to run through checklists of investigation with inefficient back-and-forth. We’ve been able to speed up the resolution time and even help many devs self-serve when things go wrong, reducing our platform support burden.
Improvement: Add introspection for everything
We instrument nd with traces and event logging to understand what our developers are doing and where things go wrong. These traces not only enable us to improve nd as platform, but also allow our developers to debug the tooling and their local services.
nd gen code got slow, but we used tracing to identify and fix it.
The result of these speed ups still impact every pipeline that developers have to run.
Another example was that a single flag caused nd env create to fail consistently.
We discovered it through anonymized usage patterns and removed the flag entirely, saving our developers the headache of trying to debug it themselves and our team—or at least whoever was on-call at the time—from hopping on a Slack huddle to figure it out.
These insights help us evolve nd without waiting for someone to file a bug. They also help developers become familiar with observability tooling early—if you’re tracing your own tools, you’re more likely to trace your services in prod.
What are we evolving next?
We’re looking to continue our adventures in bazel-ifying our developer workflows, extending it to handle parts of our repo beyond go and proto, and moving more of our code generation logic into bazel to reduce the manual steps developers need to remember to run.
We’re also always tuning our error messages to ensure developers know what to do when things go wrong.
I can’t wait to share more about those evolutions once they’ve shipped and had time to settle. Until then, I hope these principles gave you some ideas of what you could implement next in your own developer tooling.
Do you like to talk about dev tooling, environments, or developer efficiency? I’d love to chat, swap stories, and learn together! Reach me at james@ngrok.com or https://www.linkedin.com/in/jtszalay.